As with the last launch I wrote about, this is another collaboration with South Side Hackerspace: Chicago (SSH:C) studying the effects of solar maximum as part of the NEBP. Yes, they know the eclipse was last year ;)
The flight took place on Sunday April 27th from about 12:00 to 2PM local time.
Launch track
Absolutely beautiful – both in weather, path, and driving distance. Couldn’t have asked for better.



Launch site: Forsythe Woods Forest Preserve, Wilmington, IL about an hour outside the city and suburbs.
Flight path took us near Lake Village, IN – about a 90 minute drive from our launch site. Since our flight plan was 2.5 hours, we were able to pack up the launch site, track, and made it to the landing site 10 minutes before landing.
Unfortunately the spot we picked to watch the payload descend put it right below the sun – so we never saw it land. However we were close enough that the Horus 4FSK DFM17 payload telemetry stream to my receiver never lost signal – even though we were 1.2km away!
This time we hit our neck lift pretty close with an ascent rate of about 5.5m/s – despite challenging ground winds. Maximum altitude recorded was 30,102m. We also got our payload train better organized than last time, so this time no tangled line on the way down.
Payloads on-board
- KD9ZZF-1 the venerable dropsonde, on it’s fourth flight, undisputed best telemetry yet again.
- KD9ZZF-11 StratoTrack APRS
- Insta360 camera – the battery pack worked and has produced an amazing full-length flight video. Viewing on a phone is fun as you can “look around”.
- Liftoff at 5 minutes in (you can enjoy our tangled safety line that didn’t release for about a minute!)
- Burst is at 1h27m so watch from a minute before that. Unfortunately it looks like the camera shoots video in 30 minute segments, and the actual burst moment was while the camera was starting a new segment.
- Landing at 1h59m
- Experimental Meshtastic payload, which I’ll talk more about below!
Amazing photo from the camera at burst:

Note that this is a 360 degree camera which can render the most amazing fish eye effect ever making it look like we’re up above the earth much higher than we are :)
Other Fun Tech
One of the SSH:C members, Andrew, has been working on an app to visualize sonde telemetry in an augmented-reality viewer. It’s web-based and in my experience only works on Android + Chrome as iOS doesn’t seem to support WebXR (yet?). Check out the code if you’re interested: https://github.com/ajs5710/locatesonde
He used it to view telemetry of our payload after launch:

Meshtastic takes flight again
I’m not the only person putting Meshtastic payloads on balloon flights, but I’m trying to learn:
- Is this detrimental to the mesh? Will a high altitude node seeing hundreds of receivers simply hit max duty cycle and cease to be of any use? We need good logs of the chUtil and airUtilTx metrics.
- Can a Meshtastic node work like a crowd-sourced payload tracker much like APRS is often used for?
Concept
The node was configured, as with other flights, in standard CLIENT mode to allow Meshtastic users to discover and message each other via the balloon node and potentially span hundreds of miles. On top of this I wanted to capture tons of telemetry, in three ways:
- On-board, logging boat loads of node information to a log file on disk for later analysis.
- Via MQTT, aggregating standard position broadcast packets on the default channel and using a centralized gateway to send data to Sondehub Amateur, relying on passive listeners.
- Broadcasting bespoke telemetry packets on a separate channel key, so as to not spam everyone’s radios, and using a receiver-connected uploader script to upload this telemetry to Sondehub Amateur under a different payload ID.
As a bonus to make it more fun, the on-board code was configured to:
- Respond to any direct message on the public channel with a position and signal report. An automated QSO bot! Thank you to Bob KE9YQ for the idea!
- Broadcast a message to the public channel every 5km altitude to say “hey I’m a balloon!”
The Build
This time I used a Frequency Labs hat attached to a Raspberry Pi. The Pi runs portduino to run the Meshtastic firmware. This is amazing – because now to run custom code outside of Meshtastic to get it to do custom things, it’s still “on board” – you’re talking to Meshtastic over TCP on localhost. It’s the fastest connection I’ve ever seen to a Meshtastic node, presumably because the bandwidth is high and the CPU running the firmware is relatively speaking huge.


Yes, the GPS receiver needs to be on a short extension away from the Meshtastic board else it will never get a fix.
This is the bot which runs on the Pi which:
- Sends downlink telemetry periodically to the BalloonData channel
- Answers DMs
- Logs data locally
- Sends broadcast messages
It’s pretty straightforward. You can modify it to work with a Meshtastic radio over serial or BLE too. Within is also code to put the GPS receiver into flight mode, using a systemd oneshot service that runs before meshtasticd starts.
This runs on a ground station node, receiving downlink telemetry packets on the BalloonData channel and uploads them to Sondehub. Pretty simple!
I probably spent more time on this code than any other part of the flight prep. This was fun to write – Meshtastic has multiple different packet types (position, node information, text message, device telemetry, and more). Packets are by default encrypted, although the default channel has a publicly known and simple key. Packets are also encoded in protobufs. To get a payload position on the map, you need to cache the node information which has it’s name. I took inspiration and a lot of copy/paste from tcivie/meshtastic-metrics-exporter (thank you!)
It’s no where near ready for use as an always-on service like the Sondehub APRS-IS gateway; at the moment it’s just a hardcoded user ID for my node, but could easily be extended to automatically classify any node in MQTT with a balloon emoji in the name as a balloon on the Sondehub Amatuer map. But…we’ll probably get a handful of inadvertent nodes on the map.
💡 if we wanted to make Meshtastic on balloons a first-class citizen, it would be a good idea to register a port number or two for specific telemetry types that we want to use on balloon payloads. This would let us pack arbitrary telemetry encoded in efficient protobufs, and client nodes would be able to clearly identify these by the port number. But – that’s a potential job for another day – this might all be a waste of effort!
Challenges inherent to Meshtastic
Position ambiguity: Meshtastic has a specific positioning packet type, but when packets are fed to the central MQTT server for centralized sharing and mapping, positions with more than 16 bits precision are filtered out. This is rather new for Meshtastic (late 2024 ish) and causes a lot of confusion. For a HAB flight, position ambiguity is rather detrimental – when a a payload lands, you really want to know where it is. 16-bit precision means that a location packet is accurate to the nearest 1194ft / 363 meters. 363 meters away from a landed payload means you can’t see it. So you need some method to get high resolution latitude/longitude upon landing, even if this is not a broadcast.
MQTT: Meshtastic nodes by default do not ship telemetry to MQTT, but there is a public server run by the maintainers team which can be turned on with a switch in the application. A lot of users use this, usually to promote discovery of other nearby node positions not yet connected to. However the Meshtastic MQTT server is busy with tens of thousands of nodes online around the world. In recent months reliability of the server has gone downhill. In the days leading up to this launch, the public MQTT server had long periods where it was impossible to connect, and then even if the gateway connected, nodes that I might be sending to were also having trouble connecting. On launch day…it wasn’t great. I’ve since set up an UptimeRobot TCP probe for which you can view the stats; there’s been some activity to work on it since then.
Stuff I learned while developing all this:
- When you ask the Meshtastic node via the Python API where your own node is, it returns you a POSITION_APP structure. This structure is not your most recent unfiltered GPS position! This is the last position packet it sent. So if you’re sending both high precision and low precision packets on different channels, you’ll get back a variety of answer precision’s. In the end, to capture high resolution data, I simply grepped the meshtashticd.service logs for the most recent GPS position debugging coming from the GPS module (which updates every 10 seconds and is unfiltered) and used that in my code.
- Position ambiguity doesn’t affect altitude – the altitudes I broadcast and captured from MQTT seem to have no loss of accuracy and match up with the unfiltered data which I logged on-board.
- You can send high resolution position packets, but the public MQTT server will filter them out. You can also send private app messages, but the public MQTT server filters these out too.
Flight Data
I collected a lot of data…but…not quite enough! Highlights / challenges:
- The telemetry downlink on the BalloonData channel worked great to my ground station…until it didn’t. I only had a couple of remote listeners, and they saw very few packets.
- Very few listeners were connected to MQTT that day. Only two nodes relayed packets into MQTT which the uploader caught and sent to SondeHub. My own nodes did not – presumably because they were busy running the uploader script. 🤔
- The chUtil and airUtilTx metrics logged by the node seem impossible. On the ground sending messages rapidly I found I could get airUtilTx over 10% or 20% easily. The numbers here cannot be real.
- The payload rebooted a couple of times. I think this was a power supply issue. AA’s rattling around in a spring loaded battery case. How many times will I suffer the same mistake before I adapt.
- On-boarding logging of node information didn’t work. I don’t know why, I didn’t test the code much before flight. So I logged some 30,000 node information packets which were all stale :)
Here’s a graph of the three telemetry streams – the 4FSK payload in light blue for reference, the packets received and relayed by the hab-uploader on the BalloonData channel in red, and the MQTT packets in yellow. It’s interesting how as the MQTT listeners got more data, the BalloonData stops coming through. Related? Quite likely.
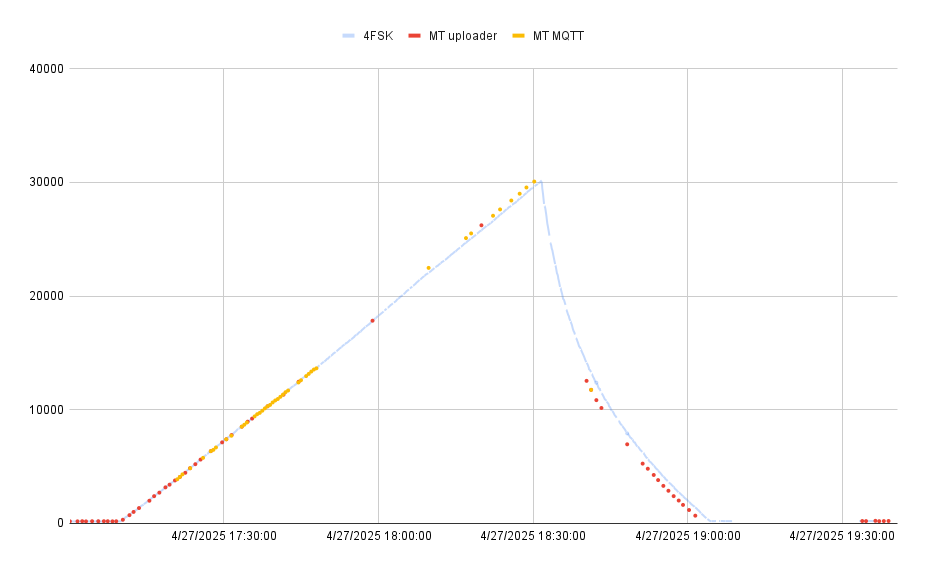
The BalloonData (“MT uploader”) transmits once per minute and ground stations received 51 of the 113 transmitted packets during flight.
The MQTT feed should get position telemetry every 30 seconds…but we got 44 of an optimistic 226 packets.
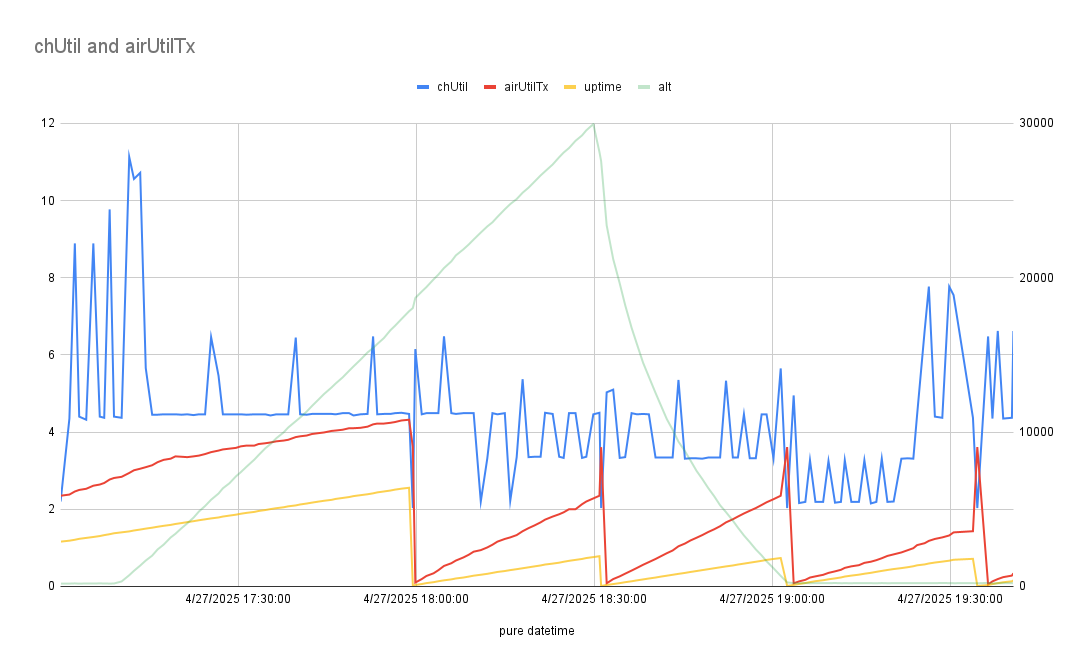
The air/channel utilization data, overlaid with uptime for fun:

chUtil never goes over 10% during flight? These numbers are strangely low.
Hypothesis: I think the radio’s receive sensitivity is incredibly low. In anecdotal ground testing, I found my Rak node (which has a less powerful transmitter) to have better signals with other nodes using my roof-mounted antenna. Reading through the meshtasticd logs, I observed that when transmitting the radio seemed to never detect any incoming packets and always went ahead and transmitted. Maybe incoming signals were much too weak for it to detect the possibility of a collision?
Sadly, I never logged anyone DM’ing the bot for their automated QSO report :( Sorry Bob KE9YQ!
For a future flight:
- If MQTT is in decent shape, just use that. We can actually extract the BalloonData telemetry from MQTT, so perhaps even run my own MQTT server which feeds into the global/public server. I can then listen to whichever server is more functional, get all the same data, but combine data streams.
- Log more data. So much more.
- Solder a battery pack already.
- Sync the system clock from the GPS; this definitely confused the meshtastic daemon.
- Fly a second Meshtastic node on the same flight (probably the Rak node) and compare results? Bob KE9YQ’s idea – I like it.
- Does having a secondary channel defined mean that the radio is changing frequencies regularly, and it’s channel utilization metric may be misleading?
This is the third flight for me with a Meshtastic payload on board. More to learn!