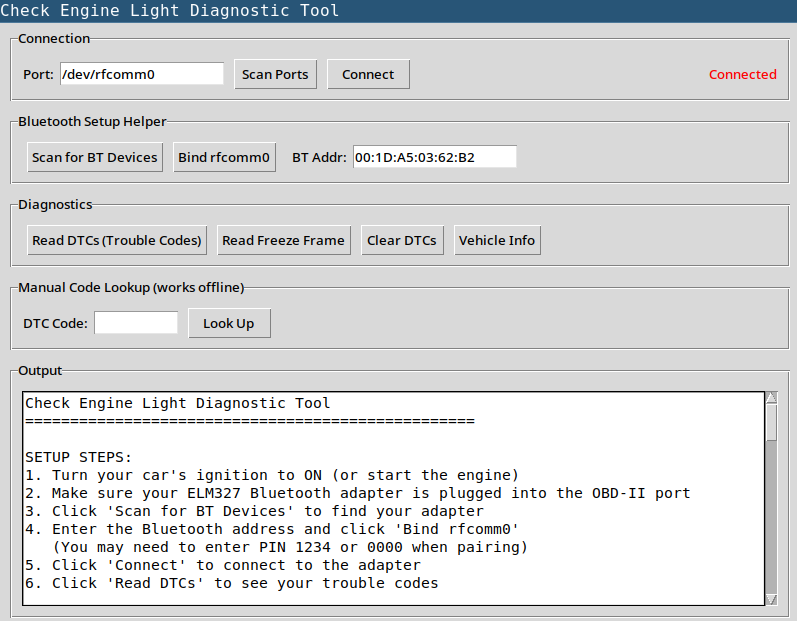
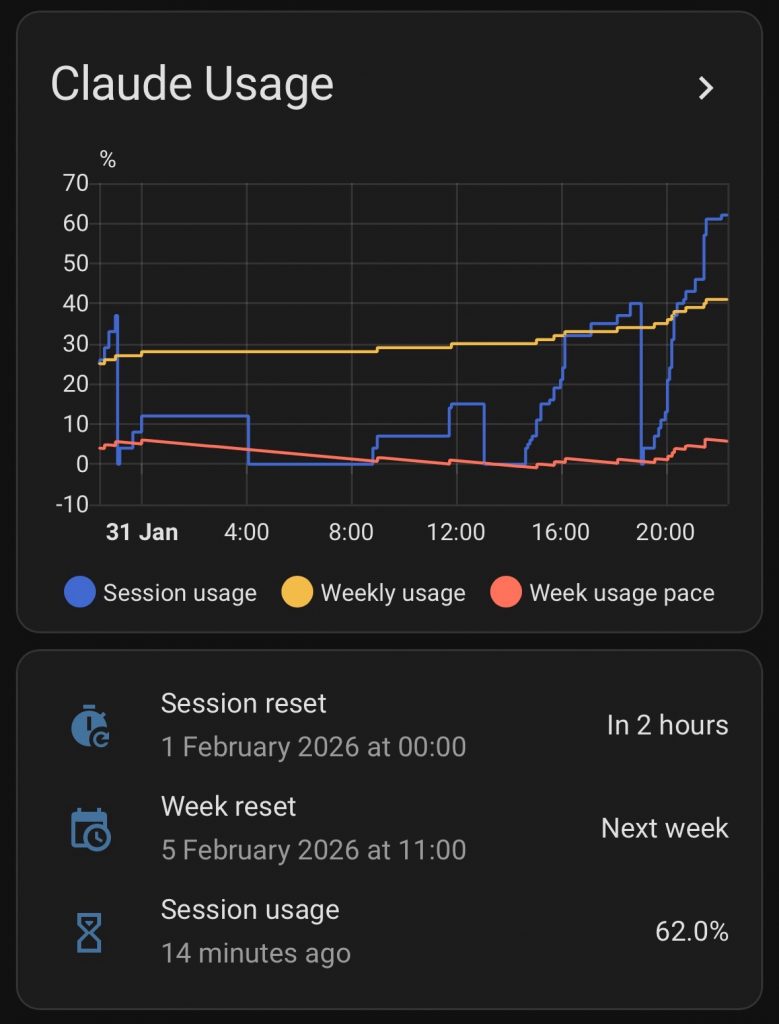
We’re staying in Cape Canaveral for a month, right before GPSL, so as is predictable of me I brought a box full of radio gear to track radiosondes, capture AIS data, and anything else that piques my interest while we’re here. I realized after texting a buddy this story that I should expand it for more to read.
I realized early on that the local Cape Canaveral Space Force Base launches old school LMS6-type radiosondes which are not as common as RS41 and DFM sondes. There I was the other day, watching a sonde come in for landing 2km from me, listening to the signal on my HT, without a decoder. My RTL-SDR was broken and couldn’t track it; I was wishing that rdz_ttgo_sonde could decode LMS6 sondes. The sonde likely landed out at sea but I was unable to track its last few km of descent.
This is the story of how I added LMS6 sthoring demoduupport to the TTGO radio, using Claude Code heavily.
I originally wrote this as a story to a friend, “I have gotten so lazy about things I used to do. I am literally programming a radio right now which is connected to my laptop on USB, across the room since I’m holding the baby, using remote control, flashing firmware, which has an experimental protocol on it that CC wrote”
It’s not laziness, it’s friction
When I say I’ve gotten lazy, what I actually mean is that the activation energy for a whole class of tasks has collapsed to near zero.
Think about what flashing firmware on an oddball radio involves. You find the right tool. You discover it needs a USB driver of some sort. You Google an error, land in a forum thread from 2014, try three things that don’t work, get annoyed, and put the radio back in the drawer. Tomorrow you’ll have the energy. Except tomorrow you don’t, and now it’s a “someday” project living in a box for a year.
The work was never the hours. The work was the walls. You’d hit one, lose momentum, and set the whole thing down. The reason these projects “took days” is that most of those days were spent not doing them.
What agentic AI actually does, for me anyway, is absorb the walls.
Predicting landfall
Side track from the programming nerdery: I did ask Cowork to build an ocean-water movement model to see where it might wash up. Ultimately the odds of me ever finding it were incredibly low and thus I did not find it, but it was fun to try and produced a beautiful artifact (click on it!)

click for the interactive analysis version
Adding the LMS6 decoder to rdz_ttgo_sonde
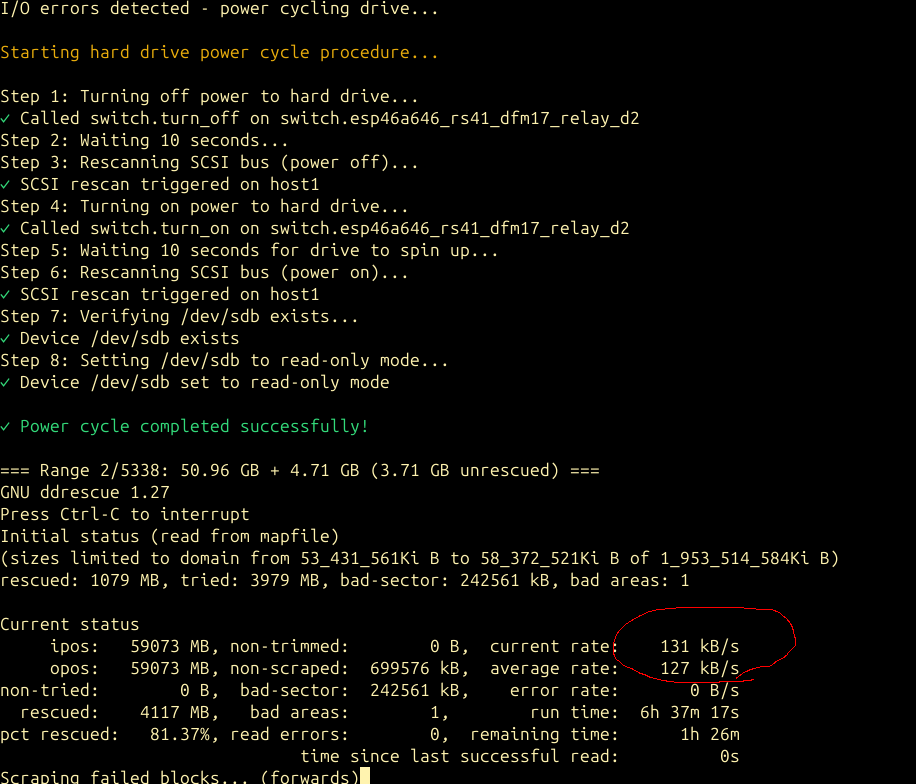
After the sonde landed I sat there thinking “this can’t be too hard to add” – but authoring demodulators like this is a field of its own, one in which I don’t have much experience. Reference code exists in the rs1729/RS project, upon which radiosonde_auto_rx uses to decode the data. The RS project is GPL-3 and rdz_ttgo_sonde is GPL-2+ so the code can be incorporated into rdz_ttgo_sonde! I asked Claude – it said the project would take days.
It was done 15 minutes later.
Code reviews, and my own skepticism, took an hour. Was this worthy of an upstream pull request? This code would be added to a binary installed on countless devices when most users will never even use it. But after some quizzing of Claude and a bit of verification myself, I’m reasonably satisfied thus far. Let’s test it!
Uploading to a new board

I plugged in a brand new TTGO Lora32 to my (also new) Mac laptop only to find I didn’t have the requisite CH34x serial driver. In 2026, serial port drivers are not yet upstream, something Linux figured out a long time ago!
Claude led me down a rabbit hole of which driver to install, but in the end, I got there (it still takes an unfortunate amount of experience to recognize when an agent hasn’t done the research for the latest information by doing a web search – it was quoting me >5 year old advice for Intel-CPU Macs).
At this point, I ran /remote-control to operate from my phone while holding a sleeping/fussy baby. One handed!
It then set up a virtualenv, installed the firmware upload utility esptool, identified the board, backed up the stock firmware for me as a convenience, and uploaded our new build of rdz_ttgo_sonde with the LMS6 patch.
I’ve done all of this before on other boards/laptops. It would’ve taken me hours (during which fussy baby would have derailed me and spread the work across a day or two). This took me less than an hour. I sat there, holding the baby, configuring my newly minted radio to join the local wifi, the frequencies and decoders to try, and more. What’s more – it connected straight to rdzSonde Go which is gratifying!
Real-world testing
Belt and braces: having just brought online a new RTL-SDR auto_rx station sitting next to the TTGO, I had an excellent local data set to test against. I don’t yet want to start uploading to Sondehub for fear of streaming errant data, so for now my goal is local logging. rdz_ttgo_sonde has AXUDP output which Claude happily wrote a logger daemon for, all to find that the AXUDP/AX25 encoding truncates the lat/lon precision that we’re receiving. There is also MQTT support which I’ve settled on as the best reference data set. Running up a Mosquitto broker and subscriber took minutes and was done mid-flight of the first or second LMS6 sonde I saw.
Initial reports showed one glaring bug: all my frames received were dated 1970-01-01. This was easy enough for Claude to spot and fix. Otherwise: frame by frame, everything I’m receiving appears identical to what I’m receiving with auto_rx.
Claude Code Monitors
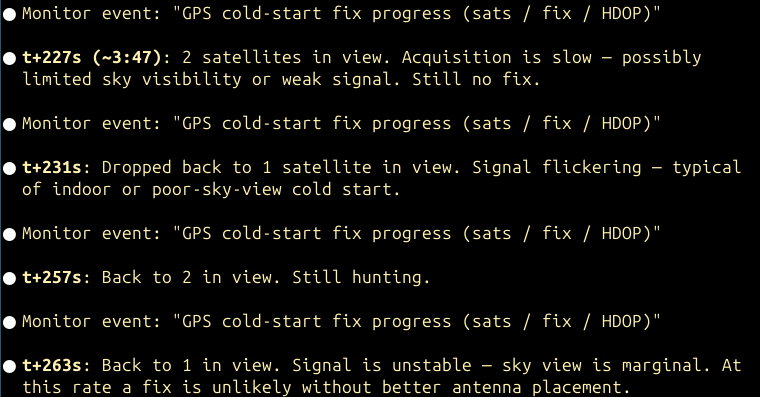
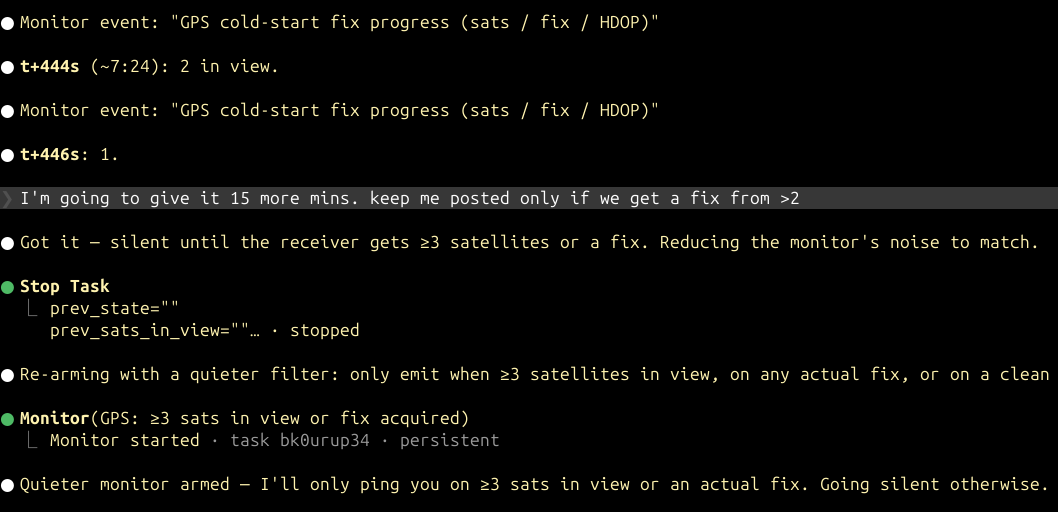
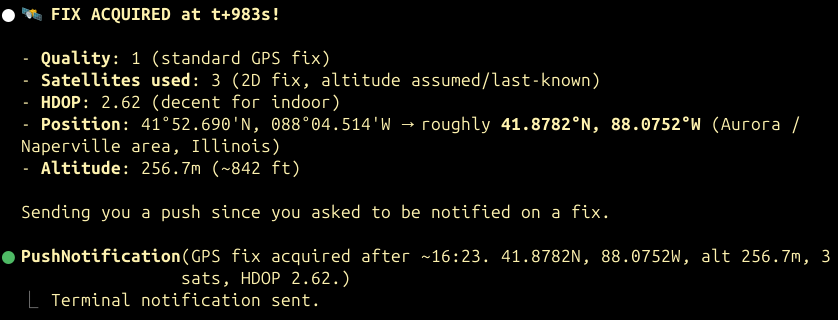
This is an excellent use case for Monitors: I have it checking in on the MQTT logs to see if we’re tracking any Sondes. Once it sees that we have – and that the flight is no longer logging on either rdz_ttgo_sonde (via MQTT) or my local auto_rx station, it runs a comparison, showing which stations received how many packets and compares frame-by-frame data.
It surprised me this evening: the Space Force launched an RS41 sonde! (Please tell me they didn’t just run out of LMS6 sondes…)
Many hats
![]()
I was motivated to add this decoder only briefly while I was short an SDR, but I was able to make excellent progress in a matter of hours across just a couple of otherwise-busy days. AI enabled me to wear many hats – ones which I’m accustomed to, but many are dusty/rusty and I would not have found the time or energy to wear:
- C++ programmer and tester not to mention modem aficionado
- ESP32 compiling guru
- MacOS sysadmin
- Data comparison and summarization
All stuff I can do – although #1 would have stopped me on investment of time. I’d rather be writing this blog, taking my kids to Kennedy Space Center, and photographing rockets!
So yes, I have gotten lazy. Lazy enough to finally get stuff done.
📧 Chasing AI: Get notified of new posts
Enter your email to be notified when I publish something new:
I’ll only email you about new blog posts. No spam.